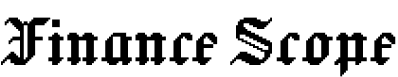

노타가 고사양 서버에서만 구동되던 1000억 개 매개변수(100B) 규모의 초대형 인공지능(AI) 모델을 로봇·자동차 등 기기 자체에서 구동할 수 있도록 만드는 메모리 압축 기술을 선보였다.
노타는 차세대 양자화 기술을 개발했다고 5일 밝혔다. 회사는 이 기술을 업스테이지의 대형언어모델(LLM) '솔라'에 적용해 모델 크기를 대폭 압축함으로써 추론 비용을 절감하고 처리 속도를 높이는 동시에, 원본 모델의 정확도를 그대로 유지했다.
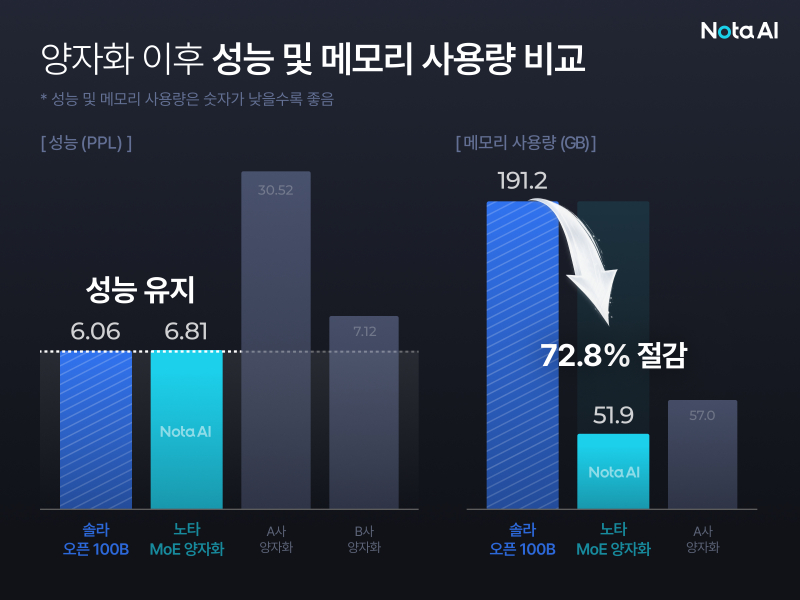
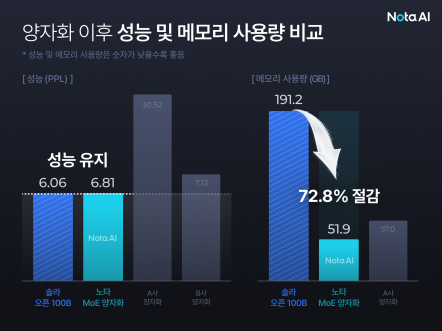
노타는 1000억 개 파라미터를 가진 '솔라 오픈 100B' 모델에 이 기술을 적용한 결과, 191.2GB에 달하던 메모리 사용량을 51.9GB까지 줄여 약 72.8%의 메모리를 절감했다. 성능지표인 PPL(Perplexity·숫자가 낮을수록 우수)은 6.81을 기록했으며, 이는 원본 모델(6.06)과 유사한 수준이다. 일부 범용 양자화 기법이 성능을 5배 이상 저하시키는 것과 달리, 노타는 성능 손실을 최소화하면서 메모리 효율을 크게 개선했다. 노타는 해당 기술에 대한 특허를 출원했다.
이번 기술은 'MoE(Mixture of Experts·전문가 혼합 구조)'의 기술적 난제를 해결했다는 점에서 주목받는다. 기존 양자화 기법은 전문가 모델별 특성을 고려하지 않고 모델 전체를 일괄 압축했다. 노타는 이 한계를 극복하기 위해 독자 알고리즘인 '노타 MoE 양자화 방법론'을 개발했다. 이 기법은 양자화 왜곡을 최소화하도록 설계됐으며, 정밀도가 필요한 부분은 유지하고 상대적으로 덜 중요한 부분만 압축해 경량화를 구현한다.
이번 개발은 과학기술정보통신부가 주도하는 '독자 AI 파운데이션 모델 프로젝트'의 일환이다. 기업들은 이 기술을 통해 고사양 GPU 인프라 없이도 신속한 AI 서비스를 제공할 수 있어 운영 비용 절감이 가능하다. 대용량 LLM을 기기 자체에 탑재할 수 있는 만큼, 로봇이나 자동차 등 피지컬 AI(온디바이스 AI) 환경에서도 고성능 AI를 안정적으로 구동할 수 있다.
채명수 노타 대표는 "이번 성과는 한국형 AI 파운데이션 모델인 솔라 100B에 노타만의 양자화 기법을 적용해 메모리를 대폭 줄이면서도 성능을 유지했다는 점에서 의미가 크다"며 "디바이스에 대규모 모델을 구현해야 하는 수요가 커질수록, 노타의 경량화·최적화 기술이 고성능 AI를 실현하는 핵심적인 역할을 해나갈 것"이라고 말했다.










